Publications
2026
- CVPR 2026 Findings
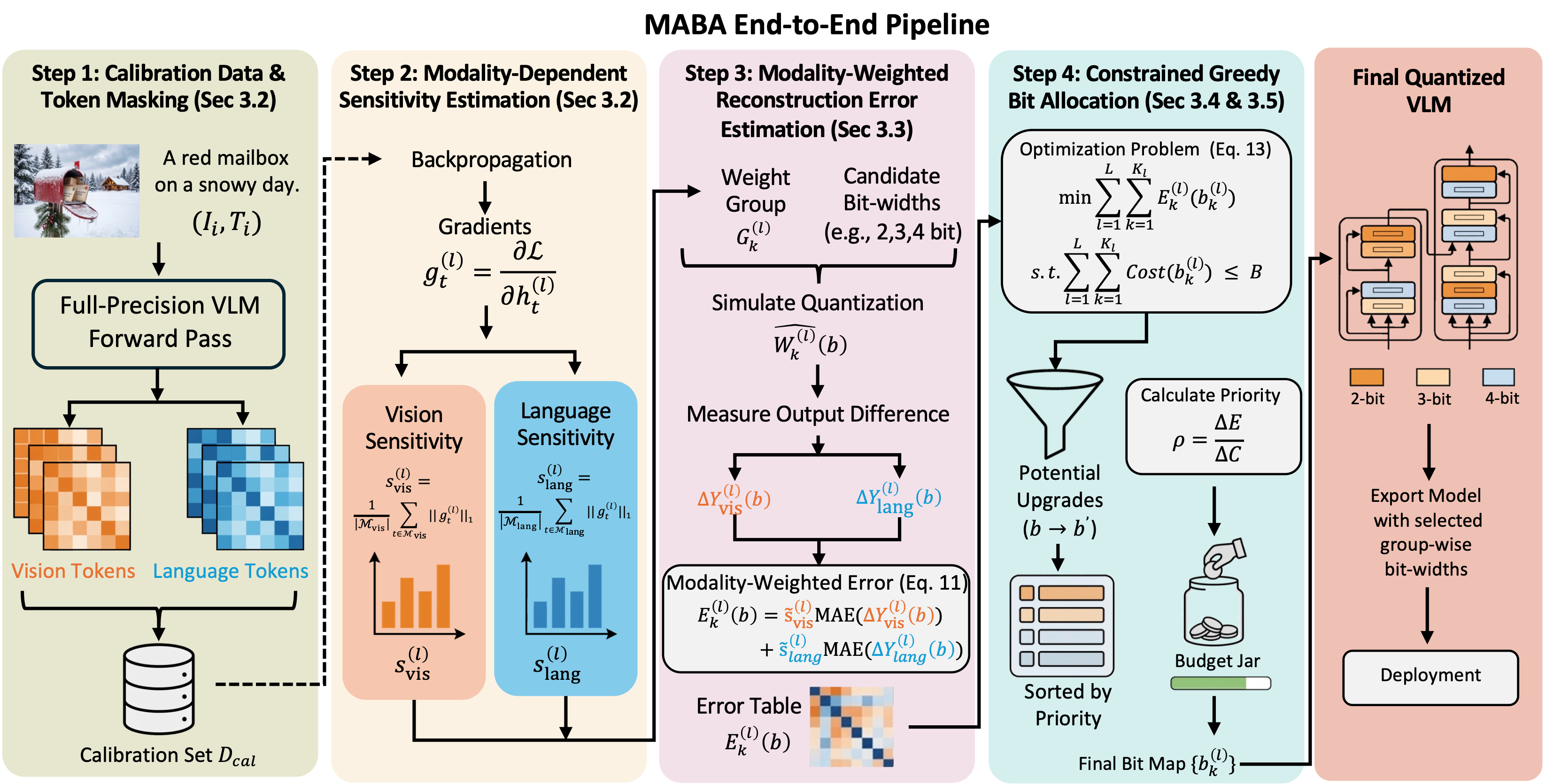 Modality-Aware Bit Allocation for Mixed-Precision Quantization of Vision-Language ModelsProceedings of the Computer Vision and Pattern Recognition Conference, 2026
Modality-Aware Bit Allocation for Mixed-Precision Quantization of Vision-Language ModelsProceedings of the Computer Vision and Pattern Recognition Conference, 2026@inproceedings{zhang2026modalityaware, title = {Modality-Aware Bit Allocation for Mixed-Precision Quantization of Vision-Language Models}, author = {Zhang, Xi and Zhu, Hanwei and Wang, Jiamang and Wu, Xiaolin and Lin, Weisi}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference}, pages = {}, volume = {}, year = {2026}, } - ICASSP 2026
 Class-Invariant Test-Time Augmentation for Domain GeneralizationZhicheng Lin, Xiaolin Wu, and Xi ZhangIEEE International Conference on Acoustics, Speech, and Signal Processing, 2026
Class-Invariant Test-Time Augmentation for Domain GeneralizationZhicheng Lin, Xiaolin Wu, and Xi ZhangIEEE International Conference on Acoustics, Speech, and Signal Processing, 2026Deep models often suffer significant performance degradation under distribution shifts. Domain generalization (DG) seeks to mitigate this challenge by enabling models to generalize to unseen domains. Most prior approaches rely on multi-domain training or computationally intensive test-time adaptation. In contrast, we propose a complementary strategy: lightweight test-time augmentation. Specifically, we develop a novel Class-Invariant Test-Time Augmentation (CI-TTA) technique. The idea is to generate multiple variants of each input image through elastic and grid deformations that nevertheless belong to the same class as the original input. Their predictions are aggregated through a confidence-guided filtering scheme that remove unreliable outputs, ensuring the final decision relies on consistent and trustworthy cues. Extensive Experiments on PACS and Office-Home datasets demonstrate consistent gains across different DG algorithms and backbones, highlighting the effectiveness and generality of our approach.
@inproceedings{lin2025class, title = {Class-Invariant Test-Time Augmentation for Domain Generalization}, author = {Lin, Zhicheng and Wu, Xiaolin and Zhang, Xi}, booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing}, pages = {}, volume = {}, year = {2026}, } - WACV 2026
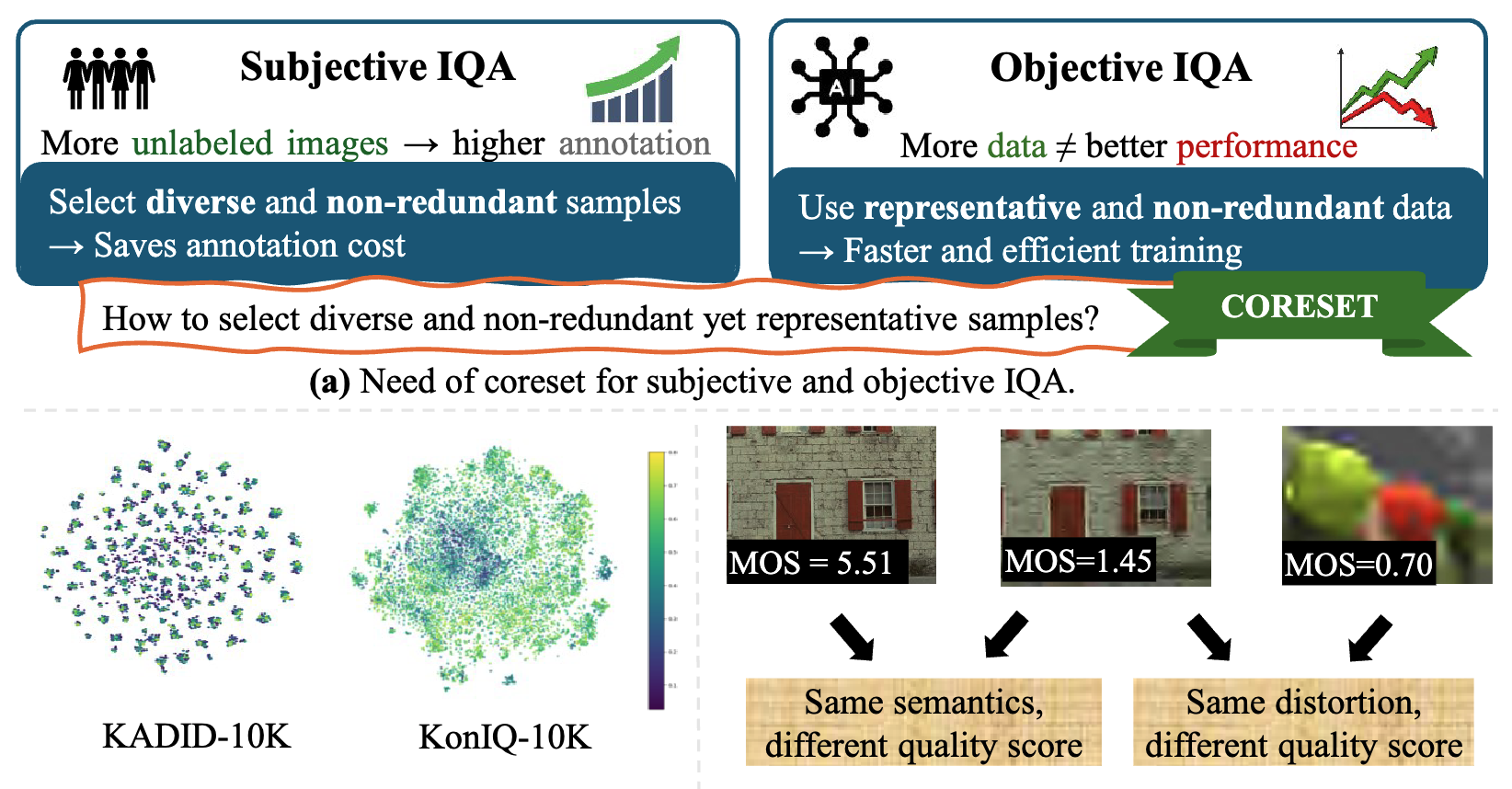 Diversity Preserving Coresets for Image Quality AssessmentWinter Conference on Applications of Computer Vision, 2026
Diversity Preserving Coresets for Image Quality AssessmentWinter Conference on Applications of Computer Vision, 2026Coresets are compact, representative subsets of large datasets. While coreset selection methods have been extensively investigated in image classification, their direct application to Image Quality Assessment (IQA) is hindered by the incoherent and structurally distinct nature of content and quality representations in IQA tasks. To address this gap, we propose Q-Diverse coreset, a framework tailored for IQA. Our method begins by extracting dual-view embeddings that are both content-aware and quality-aware, capturing semantic and perceptual nuances. Rather than directly combining these heterogeneous features, we construct separate pairwise distance matrices and fuse them in the distance space. This fusion transforms into a graph-based structure from which spectral embeddings are derived. Finally, a geometric diversity-based sampling strategy is applied in the spectral space to select a coreset that maximizes representativeness. Notably, Q-Diverse operates in a label-free manner, making it especially valuable in IQA, where collecting subjective quality annotations is computationally expensive and time-consuming. Experimental results on seven IQA benchmarks demonstrate that Q-Diverse enables the effective training of deep learning-based IQA architectures, even with limited data, impressively retaining performance. It achieves SRCC and PLCC values within 0.045 and 0.042 of those obtained from full-data training, using only 10% of the dataset on average. Our results establish Q-Diverse as a coreset selection method that enables efficient dataset curation as well as training and fine-tuning deep learning–based IQA models.
@inproceedings{Nema2026diversity, title = {Diversity Preserving Coresets for Image Quality Assessment}, author = {Nema, Arpita and Zhu, Hanwei and Zhang, Xi and Lin, Weisi}, booktitle = {Winter Conference on Applications of Computer Vision}, pages = {}, volume = {}, year = {2026}, }
2025
- NeurIPS 2025
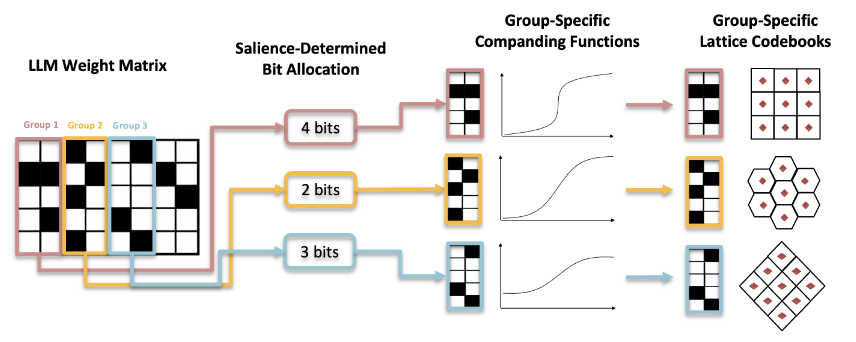 Learning Grouped Lattice Vector Quantizers for Low-Bit LLM CompressionAdvances in Neural Information Processing Systems, 2025
Learning Grouped Lattice Vector Quantizers for Low-Bit LLM CompressionAdvances in Neural Information Processing Systems, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but typically require extensive computational resources and memory for inference. Post-training quantization (PTQ) can effectively reduce these demands by storing weights in lower bit-width formats. However, standard uniform quantization often leads to notable performance degradation, particularly in low-bit scenarios. In this work, we introduce a Grouped Lattice Vector Quantization (GLVQ) framework that assigns each group of weights a customized lattice codebook, defined by a learnable generation matrix. To address the non-differentiability of the quantization process, we adopt Babai rounding to approximate nearest-lattice-point search during training, which enables stable optimization of the generation matrices. Once trained, decoding reduces to a simple matrix-vector multiplication, yielding an efficient and practical quantization pipeline. Experiments on multiple benchmarks show that our approach achieves a better trade-off between model size and accuracy compared to existing post-training quantization baselines, highlighting its effectiveness in deploying large models under stringent resource constraints.
@inproceedings{zhang2025learning, title = {Learning Grouped Lattice Vector Quantizers for Low-Bit LLM Compression}, author = {Zhang, Xi and Wu, Xiaolin and Wang, Jiamang and Lin, Weisi}, booktitle = {Advances in Neural Information Processing Systems}, pages = {}, volume = {}, year = {2025}, } - NeurIPS 2025
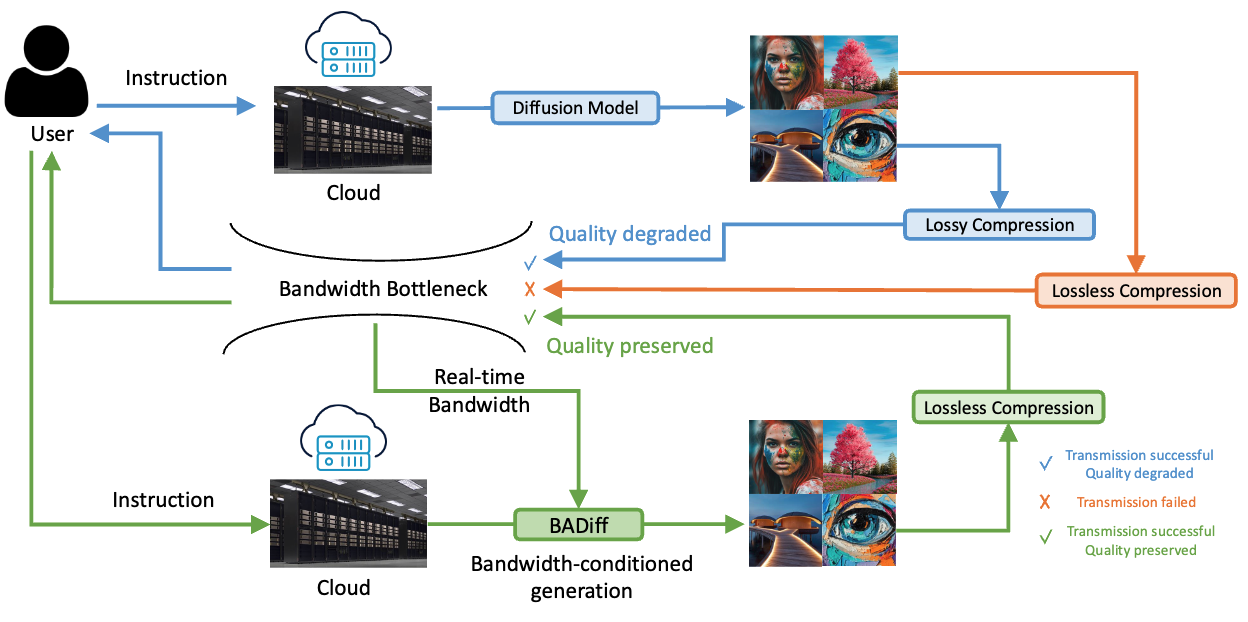 BADiff: Bandwidth Adaptive Diffusion ModelAdvances in Neural Information Processing Systems, 2025
BADiff: Bandwidth Adaptive Diffusion ModelAdvances in Neural Information Processing Systems, 2025In this work, we propose a novel framework to enable diffusion models to adapt their generation quality based on real-time network bandwidth constraints. Traditional diffusion models produce high-fidelity images by performing a fixed number of denoising steps, regardless of downstream transmission limitations. However, in practical cloud-to-device scenarios, limited bandwidth often necessitates heavy compression, leading to loss of fine textures and wasted computation. To address this, we introduce a joint end-to-end training strategy where the diffusion model is conditioned on a target quality level derived from the available bandwidth. During training, the model learns to adaptively modulate the denoising process, enabling early-stop sampling that maintains perceptual quality appropriate to the target transmission condition. Our method requires minimal architectural changes and leverages a lightweight quality embedding to guide the denoising trajectory. Experimental results demonstrate that our approach significantly improves the visual fidelity of bandwidth-adapted generations compared to naive early-stopping, offering a promising solution for efficient image delivery in bandwidth-constrained environments.
@inproceedings{zhang2025badiff, title = {BADiff: Bandwidth Adaptive Diffusion Model}, author = {Zhang, Xi and Zhu, Hanwei and Zhong, Yan and Wang, Jiamang and Lin, Weisi}, booktitle = {Advances in Neural Information Processing Systems}, pages = {}, volume = {}, year = {2025}, } - CVPR 2025 - Highlight
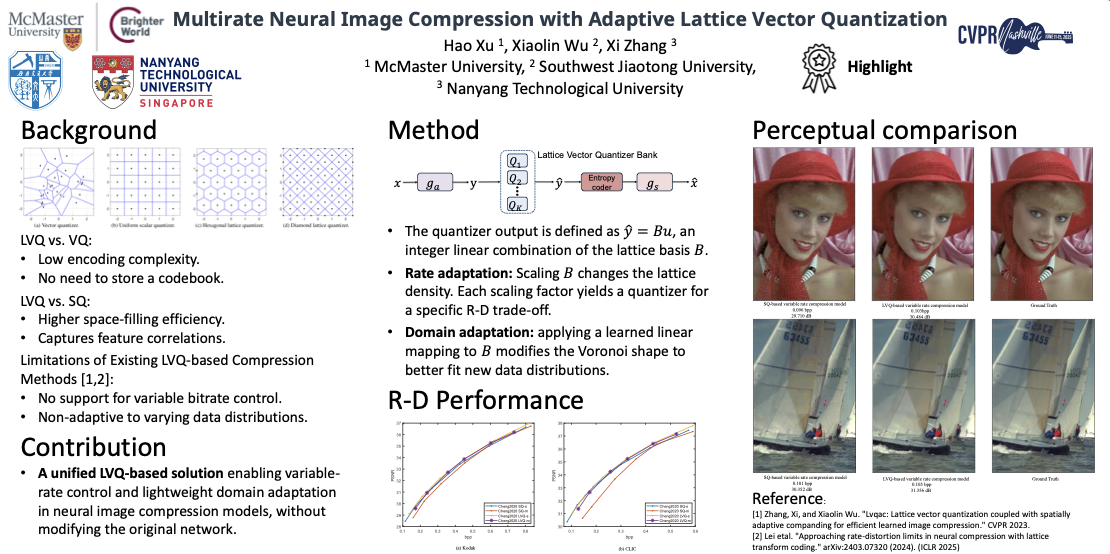 Multirate Neural Image Compression with Adaptive Lattice Vector QuantizationHao Xu, Xiaolin Wu, and Xi ZhangProceedings of the Computer Vision and Pattern Recognition Conference, 2025
Multirate Neural Image Compression with Adaptive Lattice Vector QuantizationHao Xu, Xiaolin Wu, and Xi ZhangProceedings of the Computer Vision and Pattern Recognition Conference, 2025Recent research has explored integrating lattice vector quantization (LVQ) into learned image compression models. Due to its more efficient Voronoi covering of vector space than scalar quantization (SQ), LVQ achieves better rate-distortion (R-D) performance than SQ, while still retaining the low complexity advantage of SQ. However, existing LVQ-based methods have two shortcomings: 1) lack of a multirate coding mode, hence incapable to operate at different rates; 2) the use of a fixed lattice basis, hence nonadaptive to changing source distributions. To overcome these shortcomings, we propose a novel adaptive LVQ method, which is the first among LVQ-based methods to achieve both rate and domain adaptations. By scaling the lattice basis vector, our method can adjust the density of lattice points to achieve various bit rate targets, achieving superior R-D performance to current SQ-based variable rate models. Additionally, by using a learned invertible linear transformation between two different input domains, we can reshape the predefined lattice cell to better represent the target domain, further improving the R-D performance. To our knowledge, this paper represents the first attempt to propose a unified solution for rate adaptation and domain adaptation through quantizer design.
@inproceedings{xu2025multirate, title = {Multirate Neural Image Compression with Adaptive Lattice Vector Quantization}, author = {Xu, Hao and Wu, Xiaolin and Zhang, Xi}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference}, pages = {7633--7642}, year = {2025}, }
2024
- NeurIPS 2024
 Learning Optimal Lattice Vector Quantizers for End-to-end Neural Image CompressionXi Zhang, and Xiaolin WuAdvances in Neural Information Processing Systems, 2024
Learning Optimal Lattice Vector Quantizers for End-to-end Neural Image CompressionXi Zhang, and Xiaolin WuAdvances in Neural Information Processing Systems, 2024It is customary to deploy uniform scalar quantization in the end-to-end optimized Neural image compression methods, instead of more powerful vector quantization, due to the high complexity of the latter. Lattice vector quantization (LVQ), on the other hand, presents a compelling alternative, which can exploit inter-feature dependencies more effectively while keeping computational efficiency almost the same as scalar quantization. However, traditional LVQ structures are designed/optimized for uniform source distributions, hence nonadaptive and suboptimal for real source distributions of latent code space for Neural image compression tasks. In this paper, we propose a novel learning method to overcome this weakness by designing the rate-distortion optimal lattice vector quantization (OLVQ) codebooks with respect to the sample statistics of the latent features to be compressed. By being able to better fit the LVQ structures to any given latent sample distribution, the proposed OLVQ method improves the rate-distortion performances of the existing quantization schemes in neural image compression significantly, while retaining the amenability of uniform scalar quantization.
@inproceedings{zhang2024learning, title = {Learning Optimal Lattice Vector Quantizers for End-to-end Neural Image Compression}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {Advances in Neural Information Processing Systems}, pages = {106497--106518}, volume = {37}, year = {2024}, } - ECCV 2024
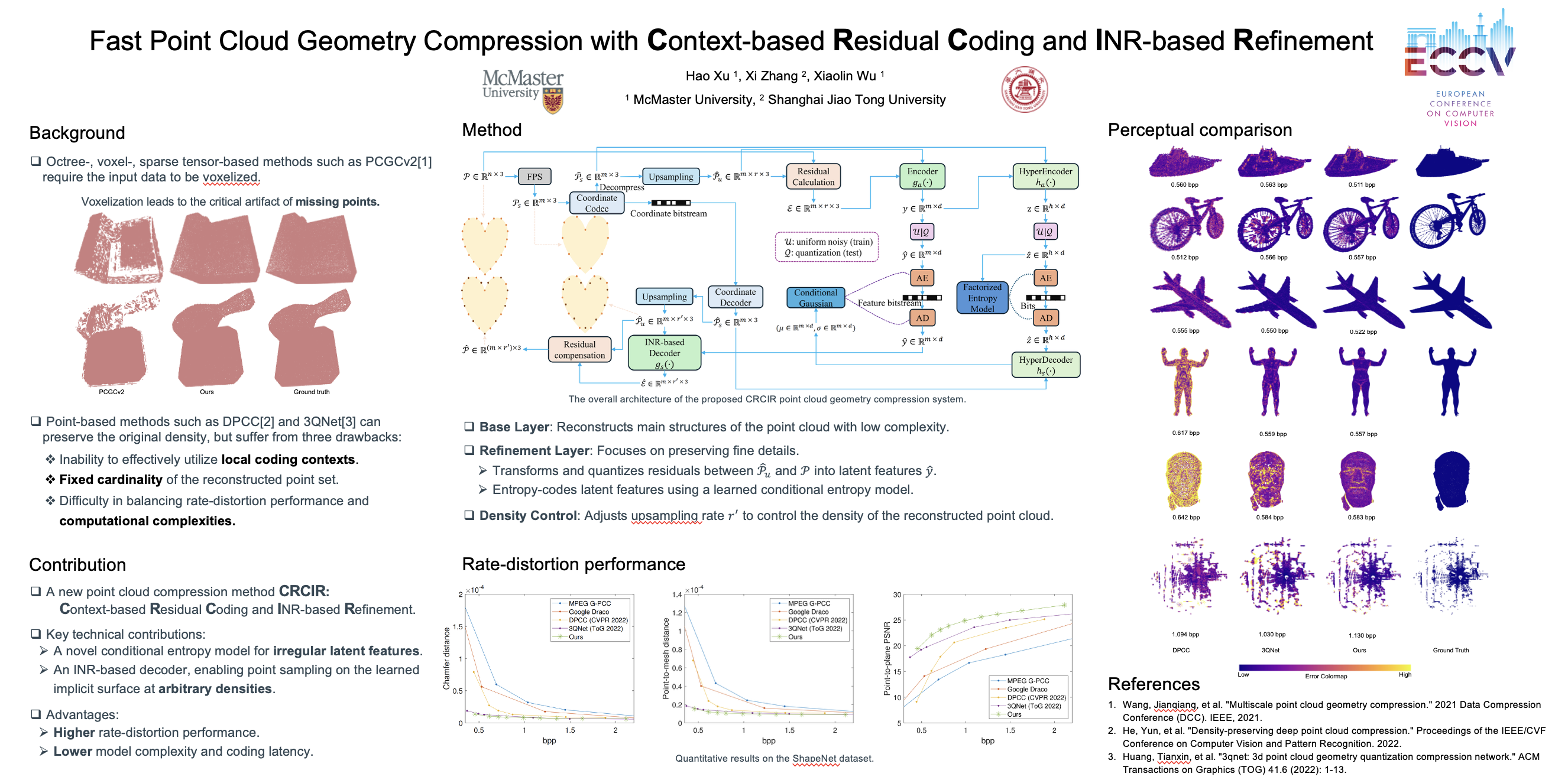 Fast Point Cloud Geometry Compression with Context-Based Residual Coding and INR-Based RefinementHao Xu, Xi Zhang, and Xiaolin WuEuropean Conference on Computer Vision, 2024
Fast Point Cloud Geometry Compression with Context-Based Residual Coding and INR-Based RefinementHao Xu, Xi Zhang, and Xiaolin WuEuropean Conference on Computer Vision, 2024Compressing a set of unordered points is far more challenging than compressing images/videos of regular sample grids, because of the difficulties in characterizing neighboring relations in an irregular layout of points. Many researchers resort to voxelization to introduce regularity, but this approach suffers from quantization loss. In this research, we use the KNN method to determine the neighborhoods of raw surface points. This gives us a means to determine the spatial context in which the latent features of 3D points are compressed by arithmetic coding. As such, the conditional probability model is adaptive to local geometry, leading to significant rate reduction. Additionally, we propose a dual-layer architecture where a non-learning base layer reconstructs the main structures of the point cloud at low complexity, while a learned refinement layer focuses on preserving fine details. This design leads to reductions in model complexity and coding latency by two orders of magnitude compared to SOTA methods. Moreover, we incorporate an implicit neural representation (INR) into the refinement layer, allowing the decoder to sample points on the underlying surface at arbitrary densities. This work is the first to effectively exploit content-aware local contexts for compressing irregular raw point clouds, achieving high rate-distortion performance, low complexity, and the ability to function as an arbitrary-scale upsampling network simultaneously.
@inproceedings{xu2024fast, title = {Fast Point Cloud Geometry Compression with Context-Based Residual Coding and INR-Based Refinement}, author = {Xu, Hao and Zhang, Xi and Wu, Xiaolin}, booktitle = {European Conference on Computer Vision}, pages = {270--288}, year = {2024}, organization = {Springer}, } - JVCI 2024
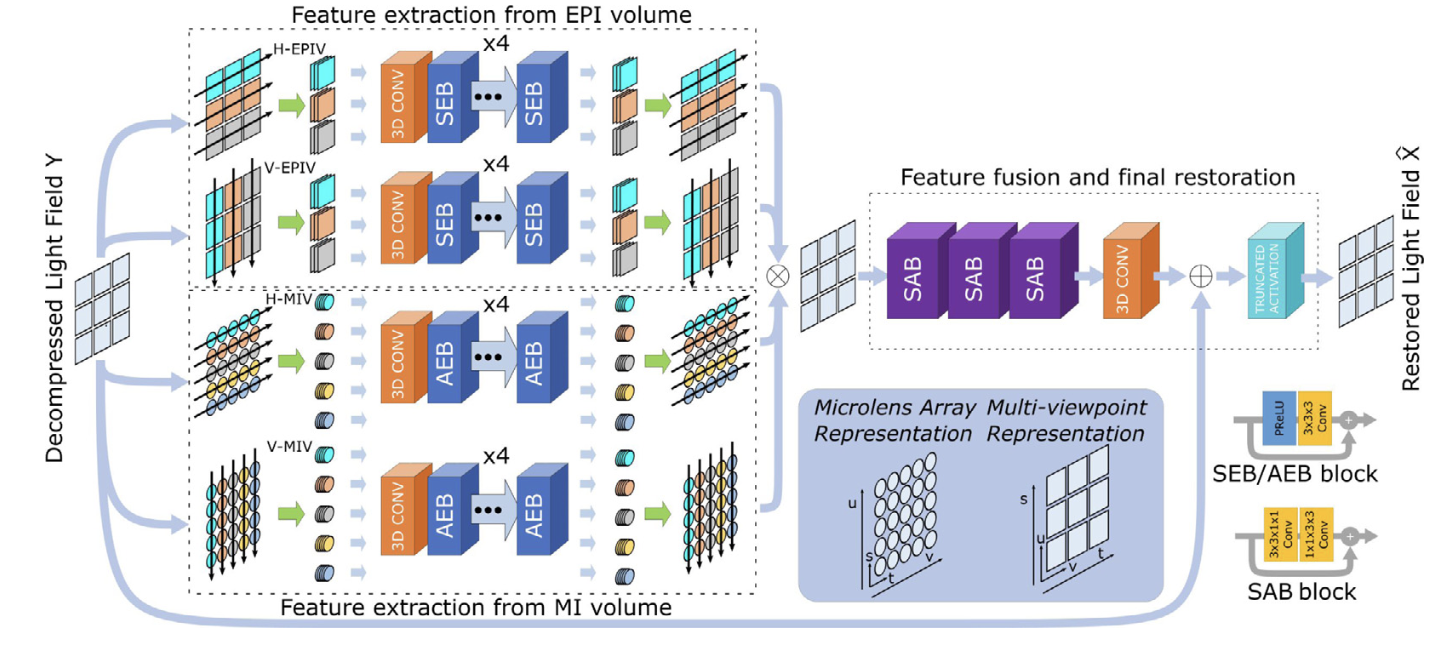 Low-complexity ℓ∞-compression of light field images with a deep-decompression stageJournal of Visual Communication and Image Representation, 2024
Low-complexity ℓ∞-compression of light field images with a deep-decompression stageJournal of Visual Communication and Image Representation, 2024To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than 100 perspectives of the same scene, resulting in large data volume. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for cost-effective light field cameras. On the other hand, existing simpler compression schemes do not offer good compression performance. In this work, we propose a novel 𝓁∞-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder enhancement. Targeting high-fidelity soft-decoding (restoration), the CNN decoding capitalizes on the 𝓁∞-constraint, i.e. the maximum absolute error bound, and light field properties to remove the compression artifacts. Two different architectures for CNN decoder enhancement are proposed, one is based on 2D CNNs and optimized for fast inference, and another is based on 3D CNNs to maximize 𝓁2 restoration quality. The proposed networks achieve superior performance both in inference speed and restoration quality in comparison to state-of-the-art light field network architectures. In conjunction with 𝓁∞-EPIC, the proposed architecture, while satisfying a well-defined 𝓁∞ constraint, outperforms existing state-of-the-art 𝓁2-based light field compression methods.
@article{mukati2024low, title = {Low-complexity ℓ∞-compression of light field images with a deep-decompression stage}, author = {Mukati, M Umair and Zhang, Xi and Wu, Xiaolin and Forchhammer, S{\o}ren}, journal = {Journal of Visual Communication and Image Representation}, volume = {99}, pages = {104072}, year = {2024}, publisher = {Elsevier}, }
2023 & Before
- CVPR 2023
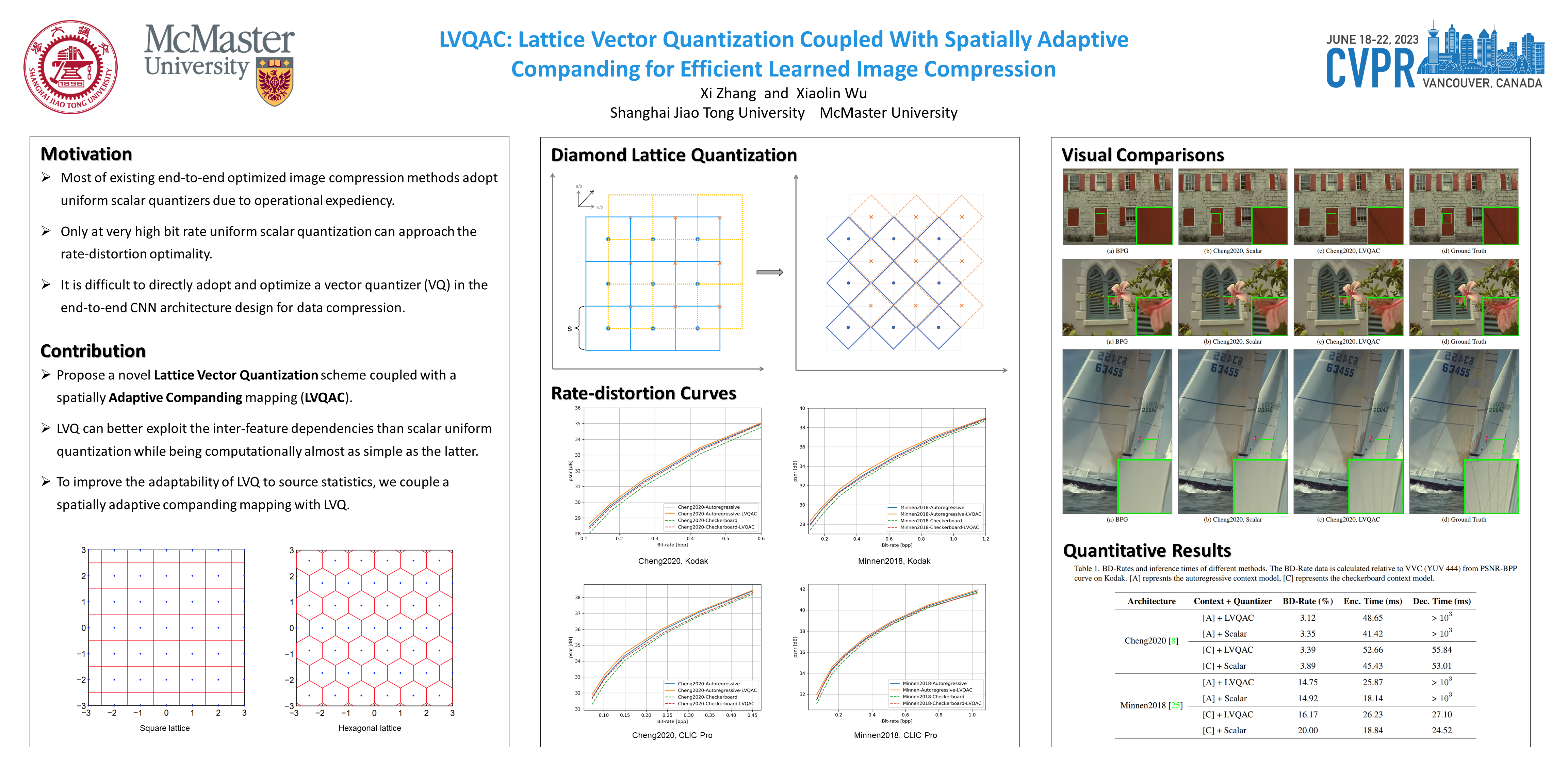 Lvqac: Lattice vector quantization coupled with spatially adaptive companding for efficient learned image compressionXi Zhang, and Xiaolin WuIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Lvqac: Lattice vector quantization coupled with spatially adaptive companding for efficient learned image compressionXi Zhang, and Xiaolin WuIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023Recently, numerous end-to-end optimized image compression neural networks have been developed and proved themselves as leaders in rate-distortion performance. The main strength of these learnt compression methods is in powerful nonlinear analysis and synthesis transforms that can be facilitated by deep neural networks. However, out of operational expediency, most of these end-to-end methods adopt uniform scalar quantizers rather than vector quantizers, which are information-theoretically optimal. In this paper, we present a novel Lattice Vector Quantization scheme coupled with a spatially Adaptive Companding (LVQAC) mapping. LVQ can better exploit the inter-feature dependencies than scalar uniform quantization while being computationally almost as simple as the latter. Moreover, to improve the adaptability of LVQ to source statistics, we couple a spatially adaptive companding (AC) mapping with LVQ. The resulting LVQAC design can be easily embedded into any end-to-end optimized image compression system. Extensive experiments demonstrate that for any end-to-end CNN image compression models, replacing uniform quantizer by LVQAC achieves better rate-distortion performance without significantly increasing the model complexity.
@inproceedings{zhang2023lvqac, title = {Lvqac: Lattice vector quantization coupled with spatially adaptive companding for efficient learned image compression}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {10239--10248}, year = {2023}, } - TPAMI 2022
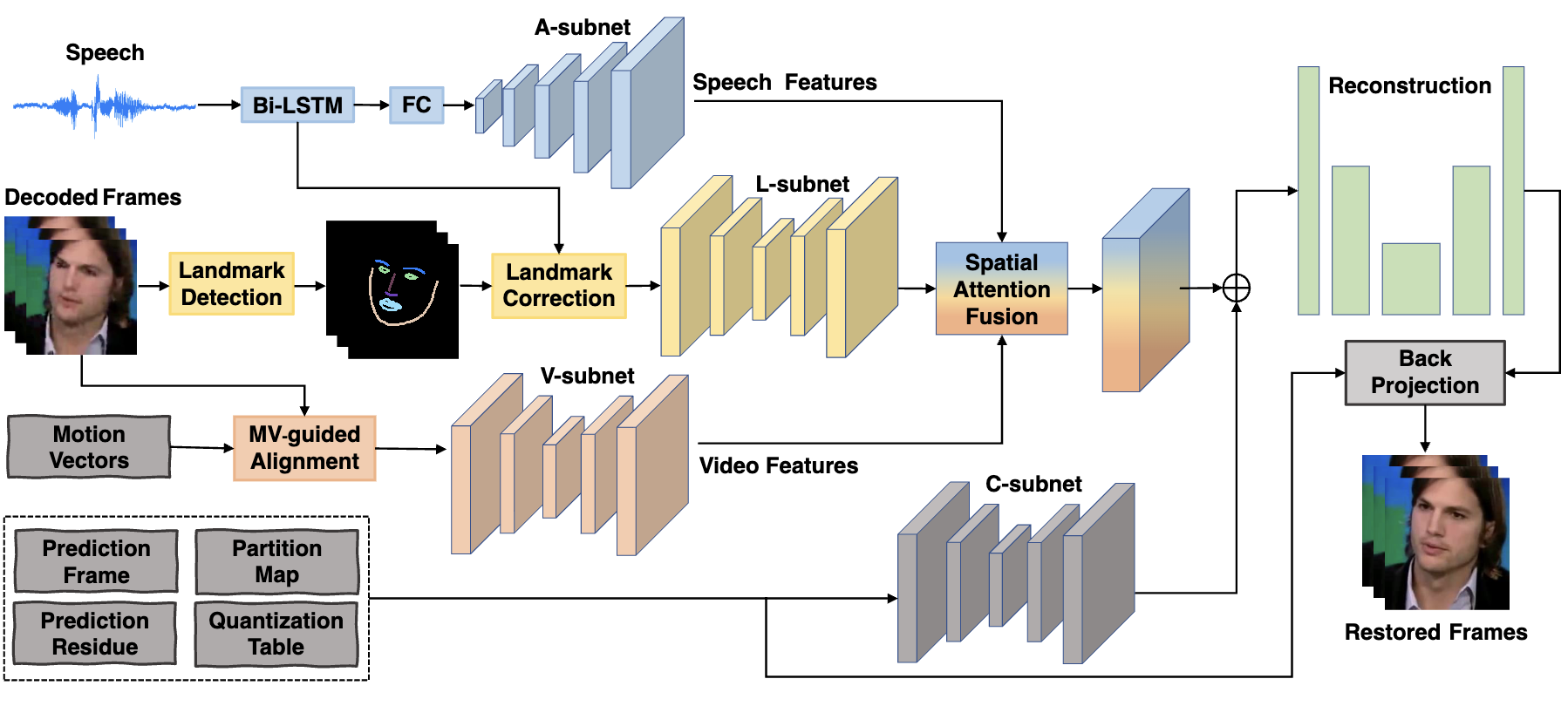 Multi-modality deep restoration of extremely compressed face videosXi Zhang, and Xiaolin WuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Multi-modality deep restoration of extremely compressed face videosXi Zhang, and Xiaolin WuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2022Arguably the most common and salient object in daily video communications is the talking head, as encountered in social media, virtual classrooms, teleconferences, news broadcasting, talk shows, etc. When communication bandwidth is limited by network congestions or cost effectiveness, compression artifacts in talking head videos are inevitable. The resulting video quality degradation is highly visible and objectionable due to high acuity of human visual system to faces. To solve this problem, we develop a multi-modality deep convolutional neural network method for restoring face videos that are aggressively compressed. The main innovation is a new DCNN architecture that incorporates known priors of multiple modalities: the video-synchronized speech signal and semantic elements of the compression code stream, including motion vectors, code partition map and quantization parameters. These priors strongly correlate with the latent video and hence they are able to enhance the capability of deep learning to remove compression artifacts. Ample empirical evidences are presented to validate the superior performance of the proposed DCNN method on face videos over the existing state-of-the-art methods.
@article{zhang2022multi, title = {Multi-modality deep restoration of extremely compressed face videos}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, volume = {45}, number = {2}, pages = {2024--2037}, year = {2022}, publisher = {IEEE}, } - CVPR 2021
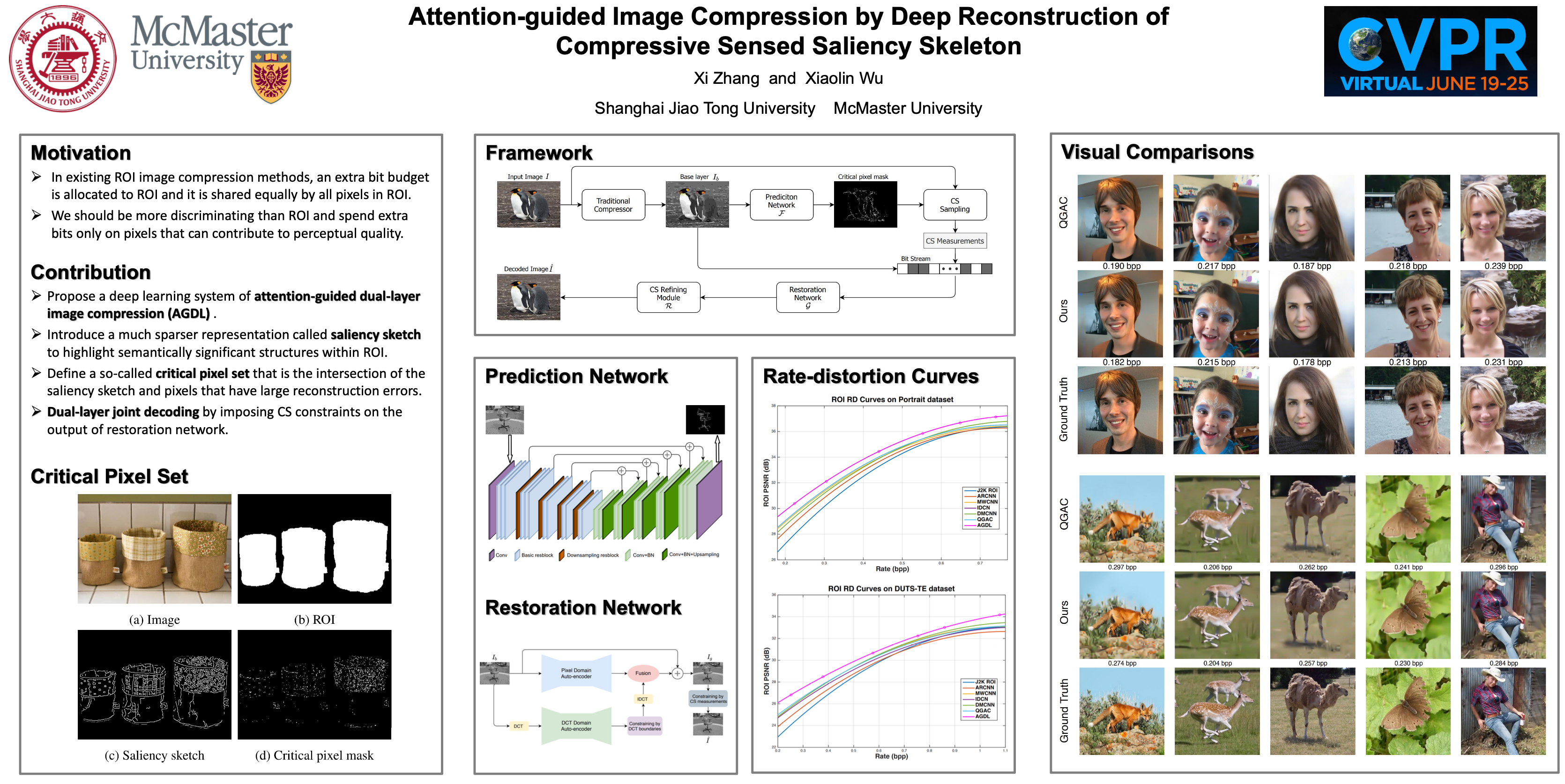 Attention-guided image compression by deep reconstruction of compressive sensed saliency skeletonXi Zhang, and Xiaolin WuIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
Attention-guided image compression by deep reconstruction of compressive sensed saliency skeletonXi Zhang, and Xiaolin WuIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021We propose a deep learning system for attention-guided dual-layer image compression (AGDL). In the AGDL compression system, an image is encoded into two layers, a base layer and an attention-guided refinement layer. Unlike the existing ROI image compression methods that spend an extra bit budget equally on all pixels in ROI, AGDL employs a CNN module to predict those pixels on and near a saliency sketch within ROI that are critical to perceptual quality. Only the critical pixels are further sampled by compressive sensing (CS) to form a very compact refinement layer. Another novel CNN method is developed to jointly decode the two compression layers for a much refined reconstruction, while strictly satisfying the transmitted CS constraints on perceptually critical pixels. Extensive experiments demonstrate that the proposed AGDL system advances the state of the art in perception-aware image compression.
@inproceedings{zhang2021attention, title = {Attention-guided image compression by deep reconstruction of compressive sensed saliency skeleton}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {13354--13364}, year = {2021}, } - TIP 2021
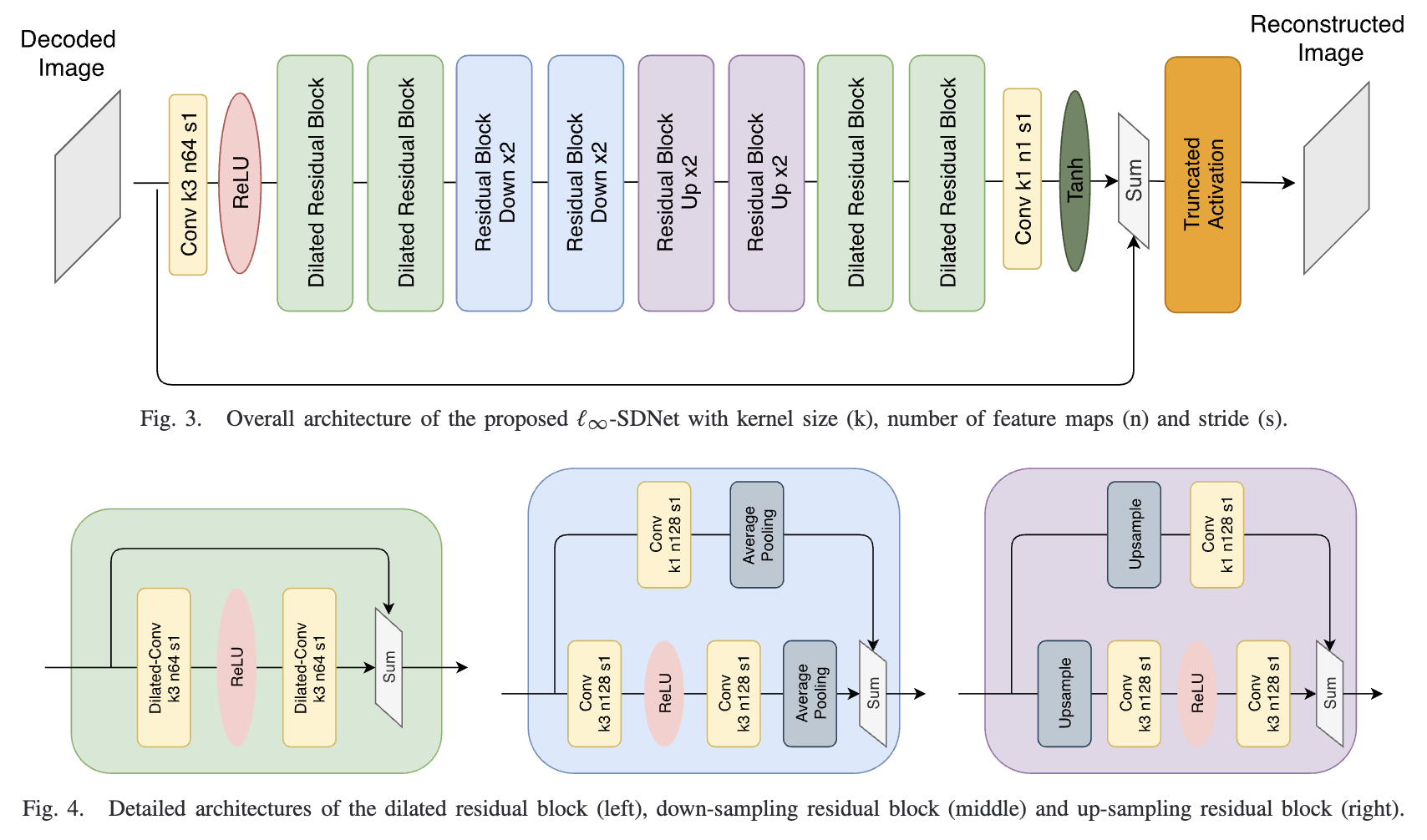 Ultra high fidelity deep image decompression with l∞-constrained compressionXi Zhang, and Xiaolin WuIEEE Transactions on Image Processing, 2021
Ultra high fidelity deep image decompression with l∞-constrained compressionXi Zhang, and Xiaolin WuIEEE Transactions on Image Processing, 2021In many professional fields, such as medicine, remote sensing and sciences, users often demand image compression methods to be mathematically lossless. But lossless image coding has a rather low compression ratio (around 2:1 for natural images). The only known technique to achieve significant compression while meeting the stringent fidelity requirements is the methodology of ℓ∞-constrained coding that was developed and standardized in nineties. We make a major progress in ℓ∞-constrained image coding after two decades, by developing a novel CNN-based soft ℓ∞-constrained decoding method. The new method repairs compression defects by using a restoration CNN called the ℓ∞-SDNet to map a conventionally decoded image to the latent image. A unique strength of the ℓ∞-SDNet is its ability to enforce a tight error bound on a per pixel basis. As such, no small distinctive structures of the original image can be dropped or distorted, even if they are statistical outliers that are otherwise sacrificed by mainstream CNN restoration methods. More importantly, this research ushers in a new image compression system of ℓ∞-constrained encoding and deep soft decoding (ℓ∞-ED2). The ℓ∞-ED2 approach beats the best of existing lossy image compression methods (e.g., BPG, WebP, etc.) not only in ℓ∞ but also in ℓ2 error metric and perceptual quality, for bit rates near the threshold of perceptually transparent reconstruction. Operationally, the new compression system is practical, with a low-complexity real-time encoder and a cascade decoder consisting of a fast initial decoder and an optional CNN soft decoder.
@article{zhang2020ultra, title = {Ultra high fidelity deep image decompression with l∞-constrained compression}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {IEEE Transactions on Image Processing}, volume = {30}, pages = {963--975}, year = {2021}, publisher = {IEEE}, } - NeurIPS 2020
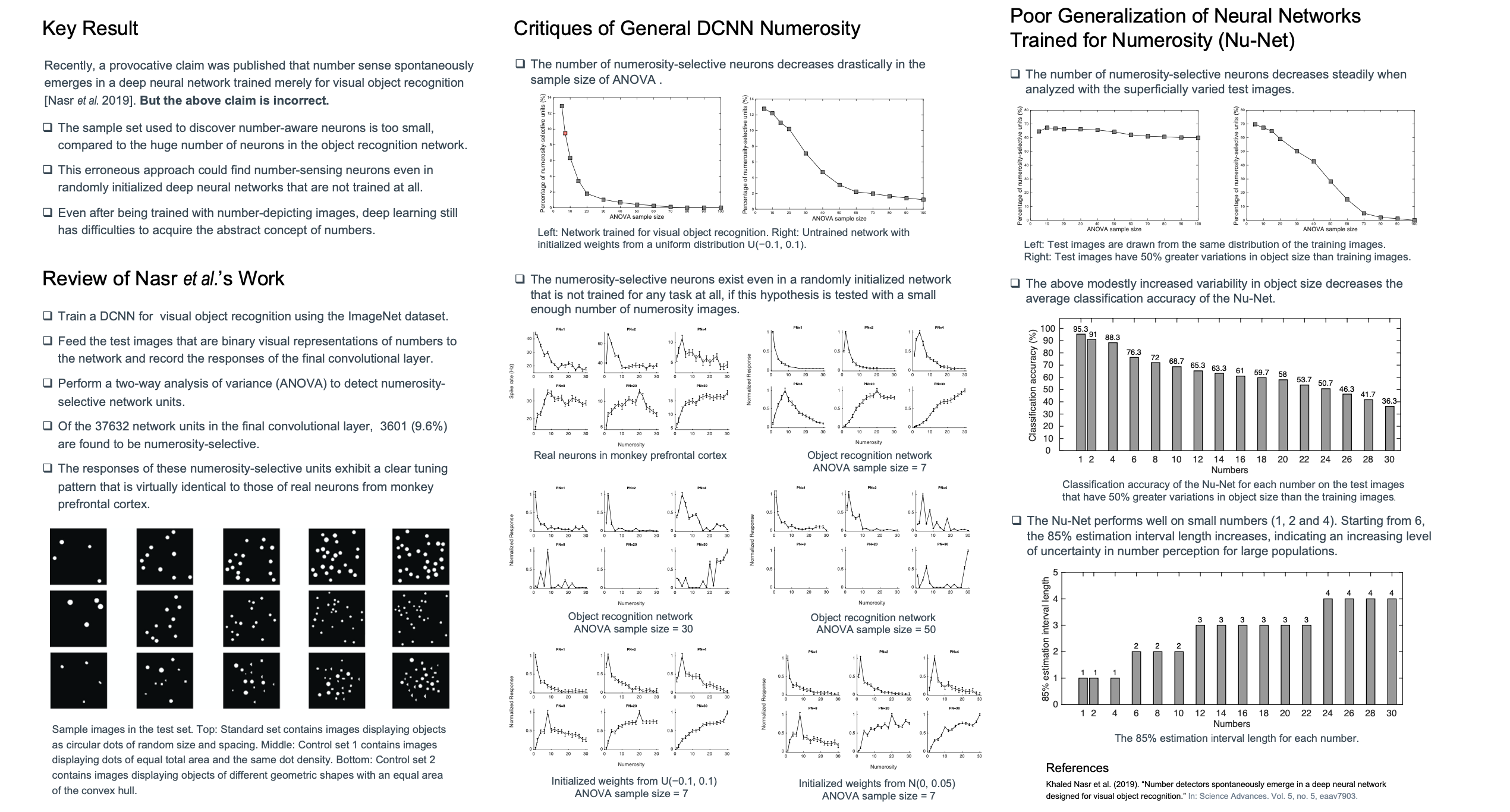 On numerosity of deep neural networksXi Zhang, and Xiaolin WuAdvances in Neural Information Processing Systems, 2020
On numerosity of deep neural networksXi Zhang, and Xiaolin WuAdvances in Neural Information Processing Systems, 2020Recently, a provocative claim was published that number sense spontaneously emerges in a deep neural network trained merely for visual object recognition. This has, if true, far reaching significance to the fields of machine learning and cognitive science alike. In this paper, we prove the above claim to be unfortunately incorrect. The statistical analysis to support the claim is flawed in that the sample set used to identify number-aware neurons is too small, compared to the huge number of neurons in the object recognition network. By this flawed analysis one could mistakenly identify number-sensing neurons in any randomly initialized deep neural networks that are not trained at all. With the above critique we ask the question what if a deep convolutional neural network is carefully trained for numerosity? Our findings are mixed. Even after being trained with number-depicting images, the deep learning approach still has difficulties to acquire the abstract concept of numbers, a cognitive task that preschoolers perform with ease. But on the other hand, we do find some encouraging evidences suggesting that deep neural networks are more robust to distribution shift for small numbers than for large numbers.
@inproceedings{zhang2020numerosity, title = {On numerosity of deep neural networks}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {Advances in Neural Information Processing Systems}, volume = {33}, pages = {1820--1829}, year = {2020}, } - CVPR 2020 - Oral
 Davd-net: Deep audio-aided video decompression of talking headsIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
Davd-net: Deep audio-aided video decompression of talking headsIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020Close-up talking heads are among the most common and salient object in video contents, such as face-to-face conversations in social media, teleconferences, news broadcasting, talk shows, etc. Due to the high sensitivity of human visual system to faces, compression distortions in talking heads videos are highly visible and annoying. To address this problem, we present a novel deep convolutional neural network (DCNN) method for very low bit rate video reconstruction of talking heads. The key innovation is a new DCNN architecture that can exploit the audio-video correlations to repair compression defects in the face region. We further improve reconstruction quality by embedding into our DCNN the encoder information of the video compression standards and introducing a constraining projection module in the network. Extensive experiments demonstrate that the proposed DCNN method outperforms the existing state-of-the-art methods on videos of talking heads.
@inproceedings{zhang2020davd, title = {Davd-net: Deep audio-aided video decompression of talking heads}, author = {Zhang, Xi and Wu, Xiaolin and Zhai, Xinliang and Ben, Xianye and Tu, Chengjie}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {12335--12344}, year = {2020}, } - ACM MM 2020
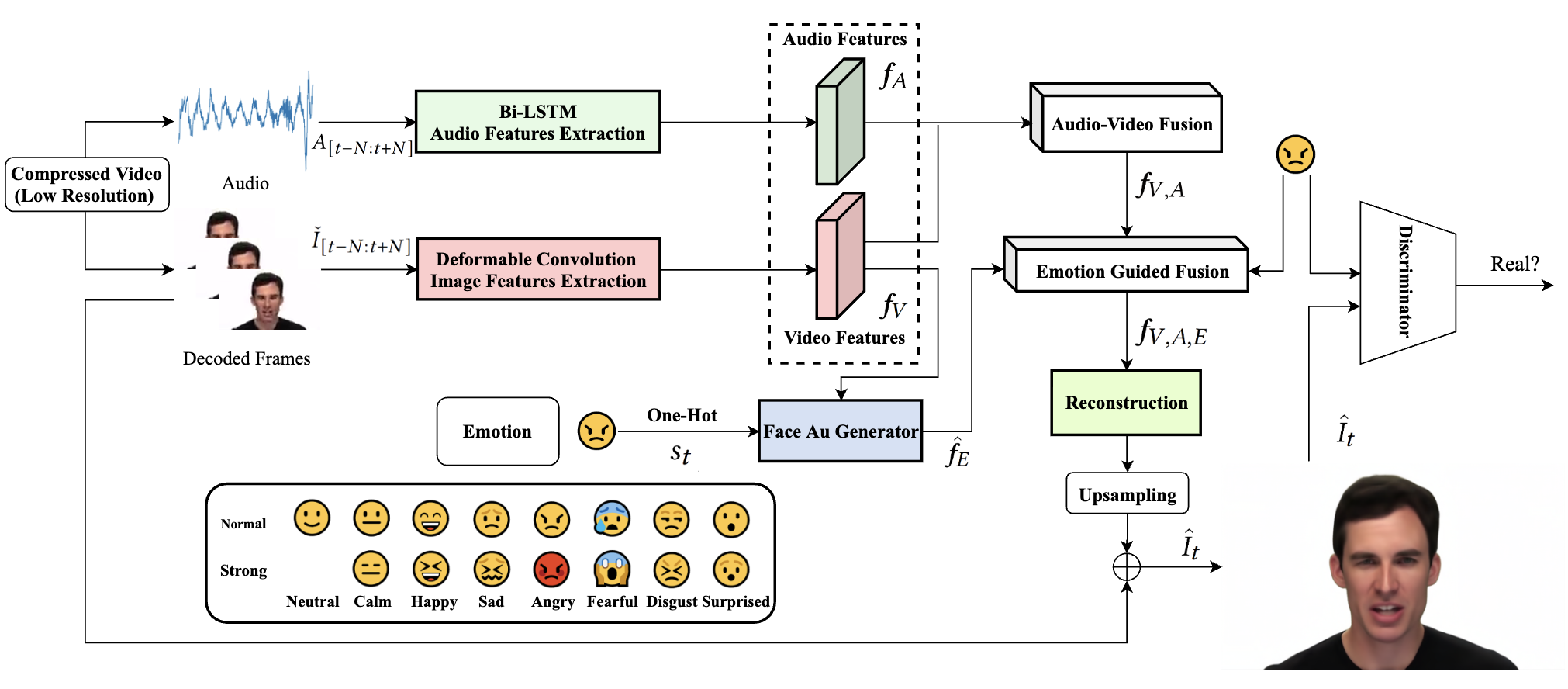 Deep multi-modality soft-decoding of very low bit-rate face videosYanhui Guo, Xi Zhang, and Xiaolin WuACM International Conference on Multimedia, 2020
Deep multi-modality soft-decoding of very low bit-rate face videosYanhui Guo, Xi Zhang, and Xiaolin WuACM International Conference on Multimedia, 2020We propose a novel deep multi-modality neural network for restoring very low bit rate videos of talking heads. Such video contents are very common in social media, teleconferencing, distance education, tele-medicine, etc., and often need to be transmitted with limited bandwidth. The proposed CNN method exploits the correlations among three modalities, video, audio and emotion state of the speaker, to remove the video compression artifacts caused by spatial down sampling and quantization. The deep learning approach turns out to be ideally suited for the video restoration task, as the complex non-linear cross-modality correlations are very difficult to model analytically and explicitly. The new method is a video post processor that can significantly boost the perceptual quality of aggressively compressed talking head videos, while being fully compatible with all existing video compression standards.
@inproceedings{guo2020deep, title = {Deep multi-modality soft-decoding of very low bit-rate face videos}, author = {Guo, Yanhui and Zhang, Xi and Wu, Xiaolin}, booktitle = {ACM International Conference on Multimedia}, pages = {3947--3955}, year = {2020}, } - AAAI 2019 - Spotlight
 Cognitive deficit of deep learning in numerosityXiaolin Wu, Xi Zhang, and Xiao ShuAAAI conference on artificial intelligence, 2019
Cognitive deficit of deep learning in numerosityXiaolin Wu, Xi Zhang, and Xiao ShuAAAI conference on artificial intelligence, 2019Subitizing, or the sense of small natural numbers, is an innate cognitive function of humans and primates; it responds to visual stimuli prior to the development of any symbolic skills, language or arithmetic. Given successes of deep learning (DL) in tasks of visual intelligence and given the primitivity of number sense, a tantalizing question is whether DL can comprehend numbers and perform subitizing. But somewhat disappointingly, extensive experiments of the type of cognitive psychology demonstrate that the examples-driven black box DL cannot see through superficial variations in visual representations and distill the abstract notion of natural number, a task that children perform with high accuracy and confidence. The failure is apparently due to the learning method not the CNN computational machinery itself. A recurrent neural network capable of subitizing does exist, which we construct by encoding a mechanism of mathematical morphology into the CNN convolutional kernels. Also, we investigate, using subitizing as a test bed, the ways to aid the black box DL by cognitive priors derived from human insight. Our findings are mixed and interesting, pointing to both cognitive deficit of pure DL, and some measured successes of boosting DL by predetermined cognitive implements. This case study of DL in cognitive computing is meaningful for visual numerosity represents a minimum level of human intelligence.
@inproceedings{wu2019cognitive, title = {Cognitive deficit of deep learning in numerosity}, author = {Wu, Xiaolin and Zhang, Xi and Shu, Xiao}, booktitle = {AAAI conference on artificial intelligence}, volume = {33}, number = {01}, pages = {1303--1310}, year = {2019}, } - ICASSP 2019
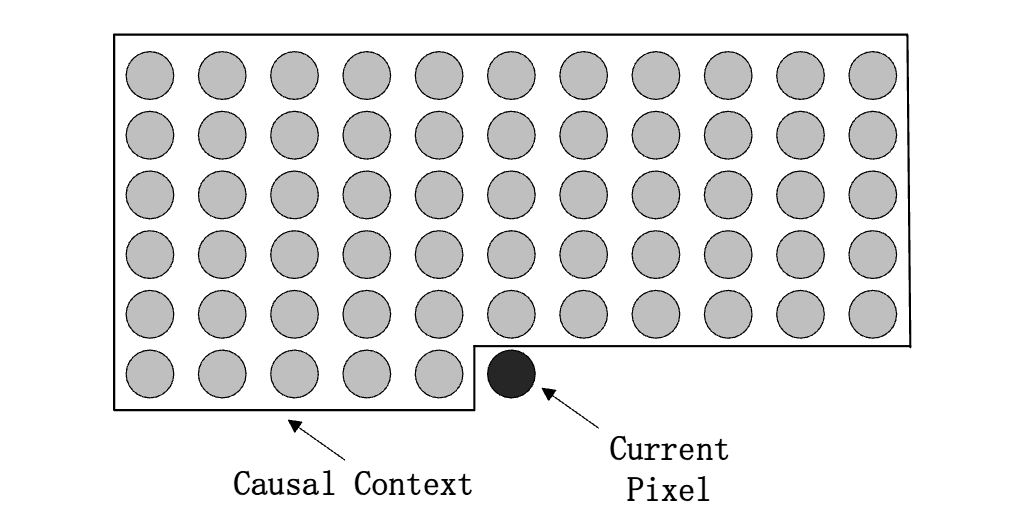 Nonlinear prediction of multidimensional signals via deep regression with applications to image codingXi Zhang, and Xiaolin WuIEEE International Conference on Acoustics, Speech and Signal Processing, 2019
Nonlinear prediction of multidimensional signals via deep regression with applications to image codingXi Zhang, and Xiaolin WuIEEE International Conference on Acoustics, Speech and Signal Processing, 2019Deep convolutional neural networks (DCNN) have enjoyed great successes in many signal processing applications because they can learn complex, non-linear causal relationships from input to output. In this light, DCNNs are well suited for the task of sequential prediction of multidimensional signals, such as images, and have the potential of improving the performance of traditional linear predictors. In this research we investigate how far DCNNs can push the envelop in terms of prediction precision. We propose, in a case study, a two-stage deep regression DCNN framework for nonlinear prediction of two-dimensional image signals. In the first-stage regression, the proposed deep prediction network (PredNet) takes the causal context as input and emits a prediction of the present pixel. Three PredNets are trained with the regression objectives of minimizing l1, l2 and l∞ norms of prediction residuals, respectively. The second-stage regression combines the outputs of the three PredNets to generate an even more precise and robust prediction. The proposed deep regression model is applied to lossless predictive image coding, and it outperforms the state-of-the-art linear predictors by appreciable margin.
@inproceedings{zhang2019nonlinear, title = {Nonlinear prediction of multidimensional signals via deep regression with applications to image coding}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing}, pages = {1602--1606}, year = {2019}, organization = {IEEE}, } - DCC 2019
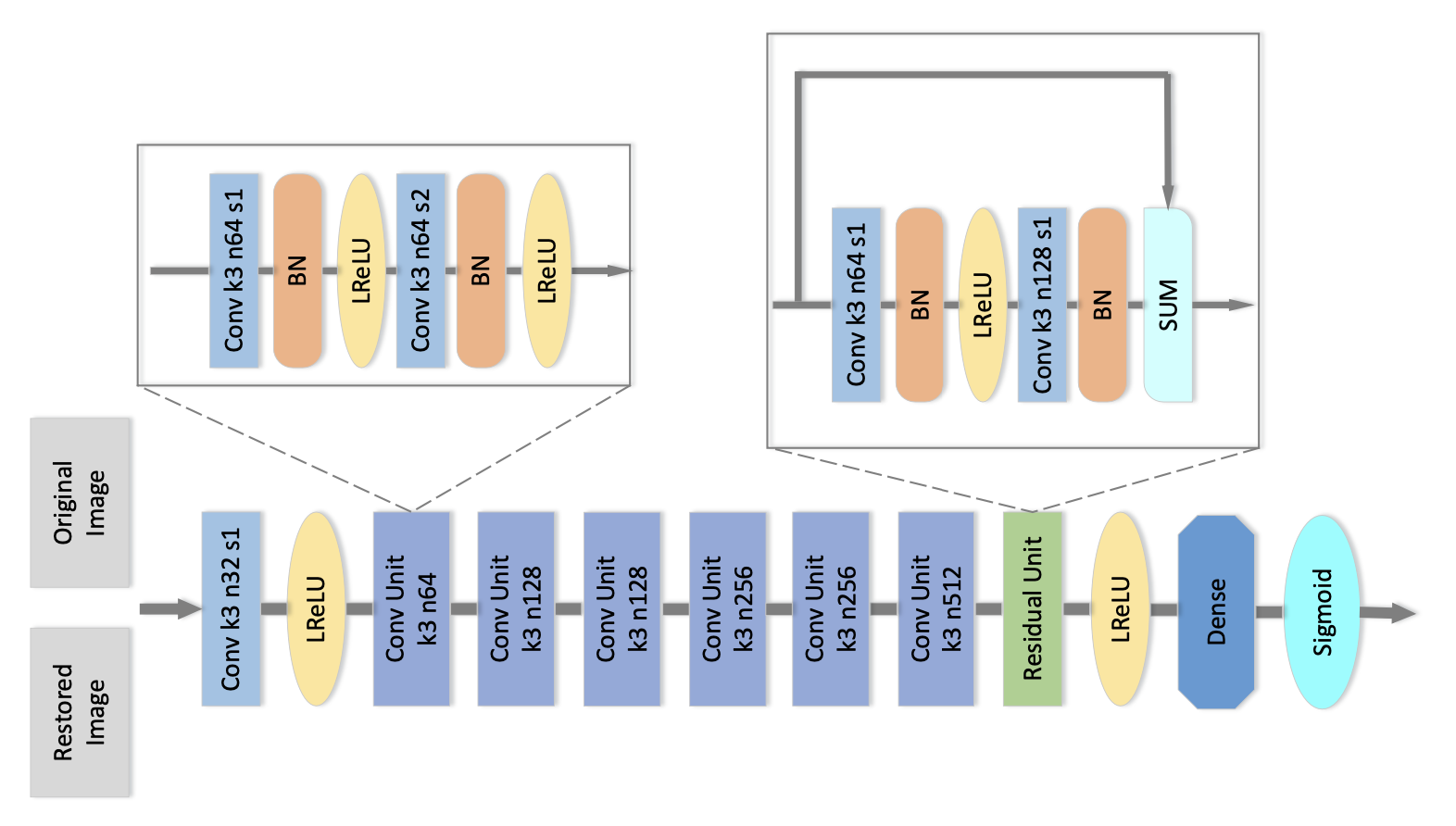 Near-lossless ℓ∞-constrained image decompression via deep neural networkXi Zhang, and Xiaolin WuData Compression Conference, 2019
Near-lossless ℓ∞-constrained image decompression via deep neural networkXi Zhang, and Xiaolin WuData Compression Conference, 2019Recently a number of CNN-based techniques were proposed to remove image compression artifacts. As in other restoration applications, these techniques all learn a mapping from decompressed patches to the original counterparts under the ubiquitous L2 metric. However, this approach is incapable of restoring distinctive image details which may be statistical outliers but have high semantic importance (e.g., tiny lesions in medical images). To overcome this weakness, we propose to incorporate an ℓ∞ fidelity criterion in the design of neural network so that no small, distinctive structures of the original image can be dropped or distorted. Experimental results demonstrate that the proposed method outperforms the state-of-the-art methods in ℓ∞ error metric and perceptual quality, while being competitive in L2 error metric as well. It can restore subtle image details that are otherwise destroyed or missed by other algorithms. Our research suggests a new machine learning paradigm of ultra high fidelity image compression that is ideally suited for applications in medicine, space, and sciences.
@inproceedings{zhang2019near, title = {Near-lossless ℓ∞-constrained image decompression via deep neural network}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {Data Compression Conference}, pages = {33--42}, year = {2019}, organization = {IEEE}, } - VCIP 2017
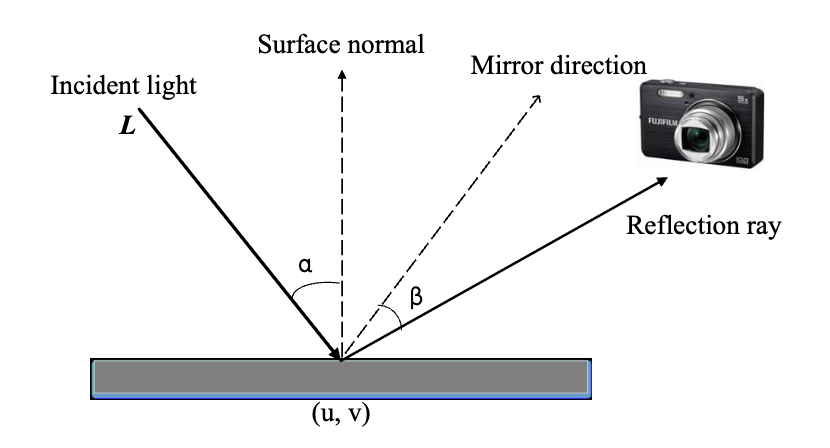 Illumination invariant feature based on neighboring radiance ratioXi Zhang, and Xiaolin WuIEEE Visual Communications and Image Processing, 2017
Illumination invariant feature based on neighboring radiance ratioXi Zhang, and Xiaolin WuIEEE Visual Communications and Image Processing, 2017In many object recognition applications, especially in face recognition, varying illuminations can adversely affect the robustness of the object recognition system. In this paper, we propose a novel illumination invariant feature called Neighboring Radiance Ratio (NRR) which is insensitive to both intensity and direction of light. NRR is derived and analyzed based on a physical image formation model. The computation of NRR does not need any prior information or any training data and NRR is far less sensitive to the border of shadows than most existing methods. The analysis of the illumination invariance of NRR is also presented. The proposed NRR feature is tested on Extended Yale B and CMU-PIE databases and compared with several previous methods. The experimental results corroborate our analysis and demonstrate that NRR is highly robust image feature against illumination changes.
@inproceedings{zhang2017illumination, title = {Illumination invariant feature based on neighboring radiance ratio}, author = {Zhang, Xi and Wu, Xiaolin}, booktitle = {IEEE Visual Communications and Image Processing}, pages = {1--4}, year = {2017}, organization = {IEEE}, }