arXiv
- arXiv
 Anisotropic Pooling for LUT-realizable CNN Image RestorationXi Zhang, and Xiaolin WuarXiv preprint arXiv:2510.21437, 2025
Anisotropic Pooling for LUT-realizable CNN Image RestorationXi Zhang, and Xiaolin WuarXiv preprint arXiv:2510.21437, 2025Table look-up realization of image restoration CNNs has the potential of achieving competitive image quality while being much faster and resource frugal than the straightforward CNN implementation. The main technical challenge facing the LUT-based CNN algorithm designers is to manage the table size without overly restricting the receptive field. The prevailing strategy is to reuse the table for small pixel patches of different orientations (apparently assuming a degree of isotropy) and then fuse the look-up results. The fusion is currently done by average pooling, which we find being ill suited to anisotropic signal structures. To alleviate the problem, we investigate and discuss anisotropic pooling methods to replace naive averaging for improving the performance of the current LUT-realizable CNN restoration methods. First, we introduce the method of generalized median pooling which leads to measurable gains over average pooling. We then extend this idea by learning data-dependent pooling coefficients for each orientation, so that they can adaptively weigh the contributions of differently oriented pixel patches. Experimental results on various restoration benchmarks show that our anisotropic pooling strategy yields both perceptually and numerically superior results compared to existing LUT-realizable CNN methods.
@article{zhang2025oaplut, title = {Anisotropic Pooling for LUT-realizable CNN Image Restoration}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {arXiv preprint arXiv:2510.21437}, year = {2025}, } - arXiv
 Receptive Field Expanded Look-up Tables for Vision Inference: Advancing from Low-level to High-level TasksXi Zhang, and Xiaolin WuarXiv preprint arXiv:2510.10522, 2025
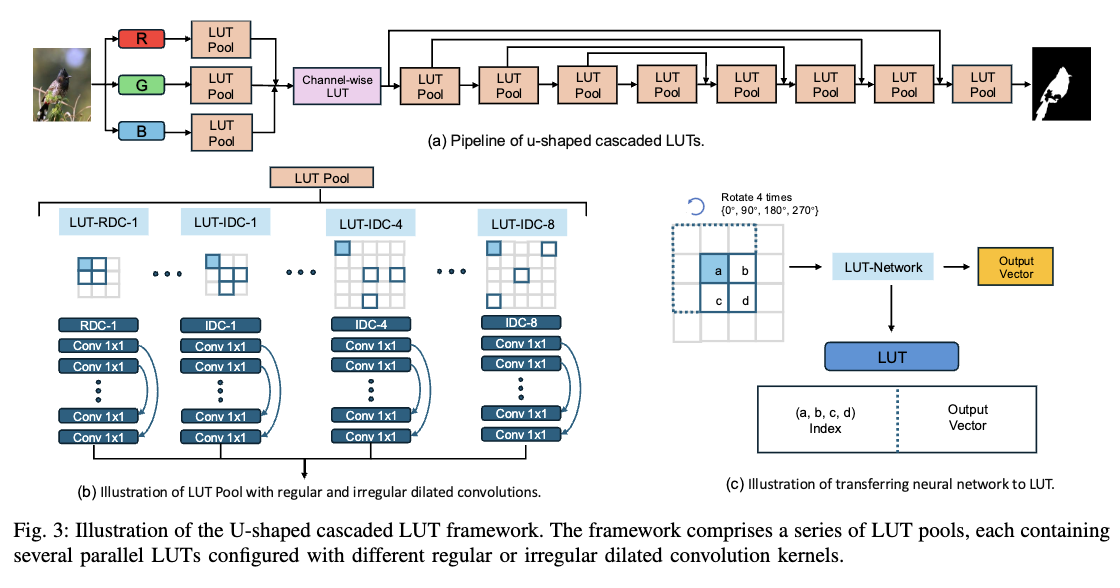
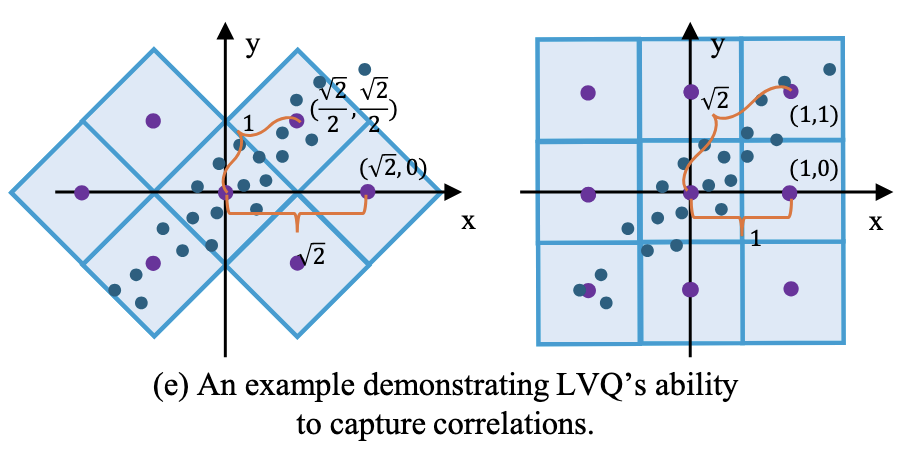
Receptive Field Expanded Look-up Tables for Vision Inference: Advancing from Low-level to High-level TasksXi Zhang, and Xiaolin WuarXiv preprint arXiv:2510.10522, 2025Recently, several look-up table (LUT) methods were developed to greatly expedite the inference of CNNs in a classical strategy of trading space for speed. However, these LUT methods suffer from a common drawback of limited receptive field of the convolution kernels due to the combinatorial explosion of table size. This research aims to expand the CNN receptive field with a fixed table size, thereby enhancing the performance of LUT-driven fast CNN inference while maintaining the same space complexity. To achieve this goal, various techniques are proposed. The main contribution is a novel approach of learning an optimal lattice vector quantizer that adaptively allocates the quantization resolution across data dimensions based on their significance to the inference task. In addition, the lattice vector quantizer offers an inherently more accurate approximation of CNN kernels than scalar quantizer as used in current practice. Furthermore, we introduce other receptive field expansion strategies, including irregular dilated convolutions and a U-shaped cascaded LUT structure, designed to capture multi-level contextual information without inflating table size. Together, these innovations allow our approach to effectively balance speed, accuracy, and memory efficiency, demonstrating significant improvements over existing LUT methods.
@article{zhang2024rfelut, title = {Receptive Field Expanded Look-up Tables for Vision Inference: Advancing from Low-level to High-level Tasks}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {arXiv preprint arXiv:2510.10522}, year = {2025}, } - arXiv
 Improving 3DGS Compression by Scene-Adaptive Lattice Vector QuantizationHao Xu, Xiaolin Wu, and Xi ZhangarXiv preprint arXiv:2509.13482, 2025
Improving 3DGS Compression by Scene-Adaptive Lattice Vector QuantizationHao Xu, Xiaolin Wu, and Xi ZhangarXiv preprint arXiv:2509.13482, 20253D Gaussian Splatting (3DGS) is rapidly gaining popularity for its photorealistic rendering quality and real-time performance, but it generates massive amounts of data. Hence compressing 3DGS data is necessary for the cost effectiveness of 3DGS models. Recently, several anchor-based neural compression methods have been proposed, achieving good 3DGS compression performance. However, they all rely on uniform scalar quantization (USQ) due to its simplicity. A tantalizing question is whether more sophisticated quantizers can improve the current 3DGS compression methods with very little extra overhead and minimal change to the system. The answer is yes by replacing USQ with lattice vector quantization (LVQ). To better capture scene-specific characteristics, we optimize the lattice basis for each scene, improving LVQ’s adaptability and R-D efficiency. This scene-adaptive LVQ (SALVQ) strikes a balance between the R-D efficiency of vector quantization and the low complexity of USQ. SALVQ can be seamlessly integrated into existing 3DGS compression architectures, enhancing their R-D performance with minimal modifications and computational overhead. Moreover, by scaling the lattice basis vectors, SALVQ can dynamically adjust lattice density, enabling a single model to accommodate multiple bit rate targets. This flexibility eliminates the need to train separate models for different compression levels, significantly reducing training time and memory consumption.
@article{xu2025salvq, title = {Improving 3DGS Compression by Scene-Adaptive Lattice Vector Quantization}, author = {Xu, Hao and Wu, Xiaolin and Zhang, Xi}, journal = {arXiv preprint arXiv:2509.13482}, year = {2025}, } - arXiv
 3DGS Compression with Sparsity-guided Hierarchical Transform CodingHao Xu, Xiaolin Wu, and Xi ZhangarXiv preprint arXiv:2505.22908, 2025
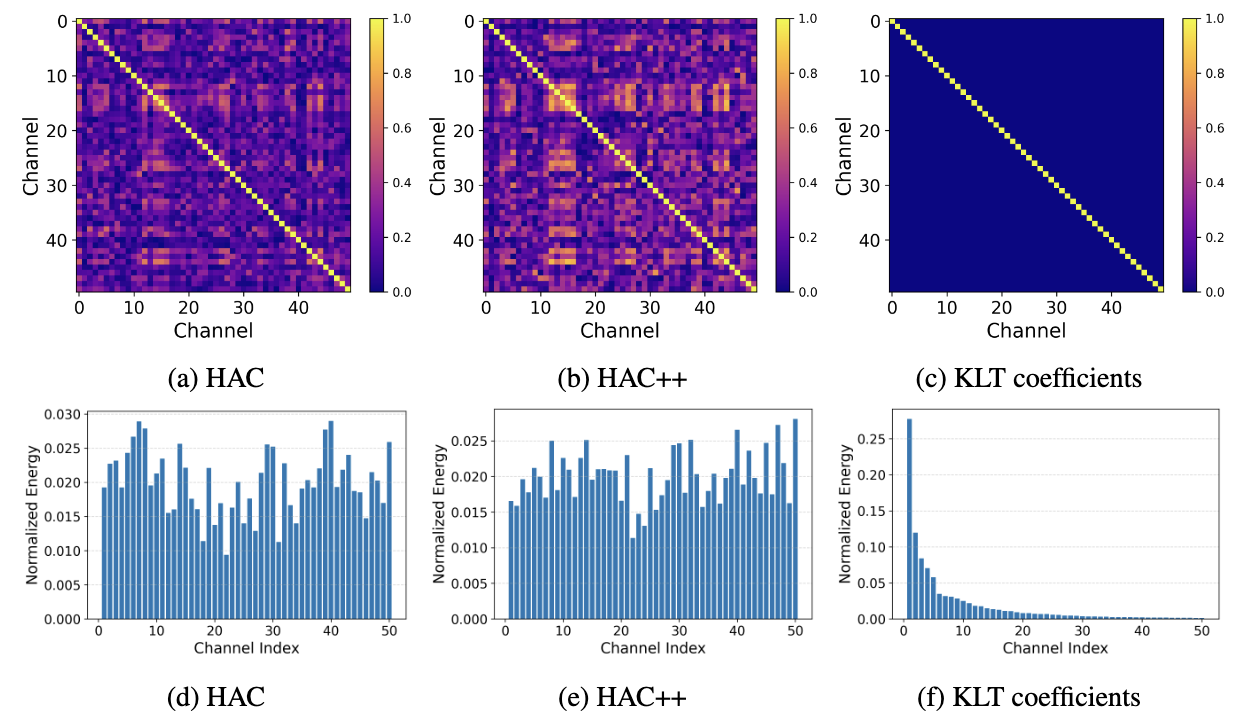
3DGS Compression with Sparsity-guided Hierarchical Transform CodingHao Xu, Xiaolin Wu, and Xi ZhangarXiv preprint arXiv:2505.22908, 20253D Gaussian Splatting (3DGS) has gained popularity for its fast and high-quality rendering, but it has a very large memory footprint incurring high transmission and storage overhead. Recently, some neural compression methods, such as Scaffold-GS, were proposed for 3DGS but they did not adopt the approach of end-to-end optimized analysis-synthesis transforms which has been proven highly effective in neural signal compression. Without an appropriate analysis transform, signal correlations cannot be removed by sparse representation. Without such transforms the only way to remove signal redundancies is through entropy coding driven by a complex and expensive context modeling, which results in slower speed and suboptimal rate-distortion (R-D) performance. To overcome this weakness, we propose Sparsity-guided Hierarchical Transform Coding (SHTC), the first end-to-end optimized transform coding framework for 3DGS compression. SHTC jointly optimizes the 3DGS, transforms and a lightweight context model. This joint optimization enables the transform to produce representations that approach the best R-D performance possible. The SHTC framework consists of a base layer using KLT for data decorrelation, and a sparsity-coded enhancement layer that compresses the KLT residuals to refine the representation. The enhancement encoder learns a linear transform to project high-dimensional inputs into a low-dimensional space, while the decoder unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) to reconstruct the residuals. All components are designed to be interpretable, allowing the incorporation of signal priors and fewer parameters than black-box transforms. This novel design significantly improves R-D performance with minimal additional parameters and computational overhead.
@article{xu20253dgs, title = {3DGS Compression with Sparsity-guided Hierarchical Transform Coding}, author = {Xu, Hao and Wu, Xiaolin and Zhang, Xi}, journal = {arXiv preprint arXiv:2505.22908}, year = {2025}, } - arXiv
 FLLIC: Functionally Lossless Image CompressionXi Zhang, and Xiaolin WuarXiv preprint arXiv:2401.13616, 2024
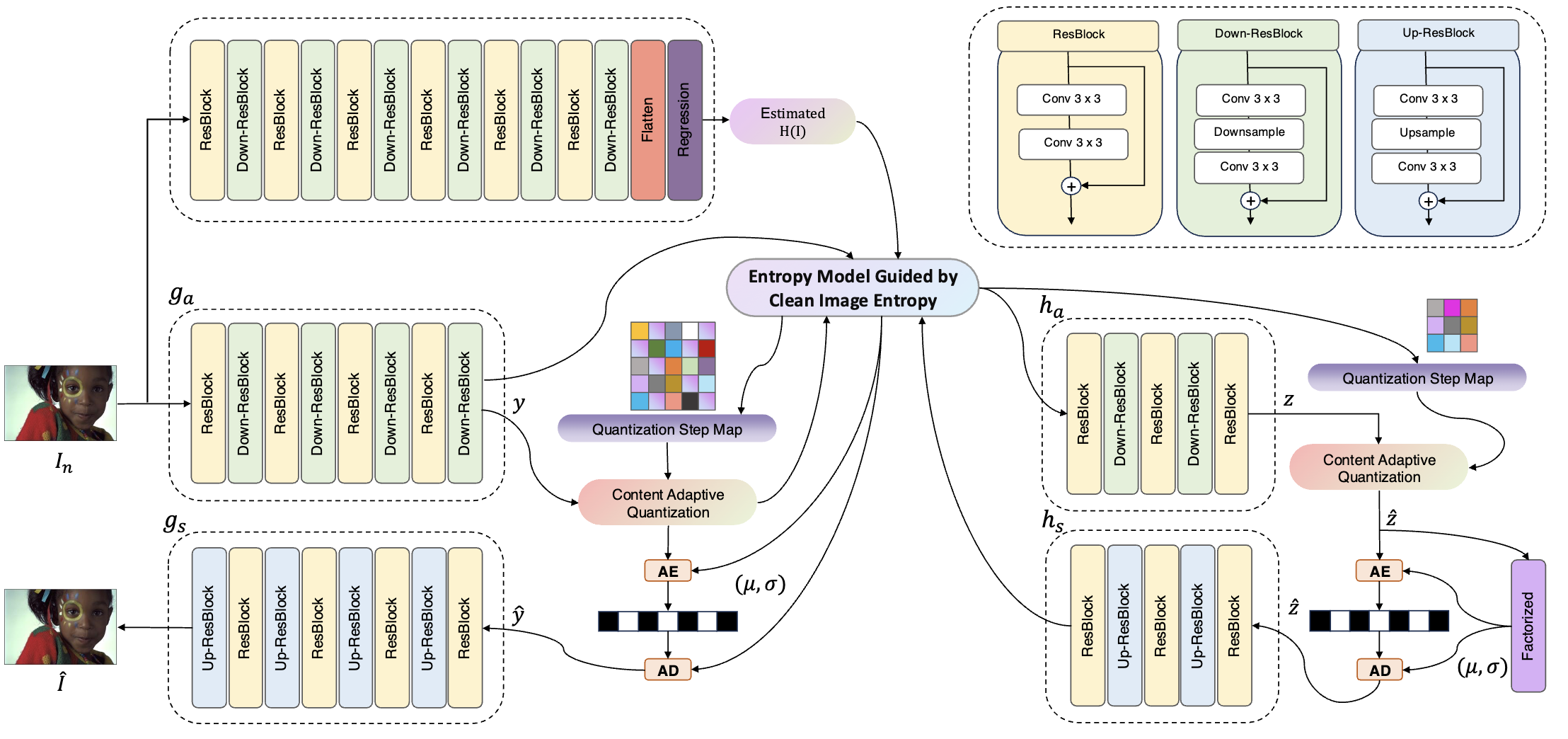
FLLIC: Functionally Lossless Image CompressionXi Zhang, and Xiaolin WuarXiv preprint arXiv:2401.13616, 2024Recently, DNN models for lossless image coding have surpassed their traditional counterparts in compression performance, reducing the previous lossless bit rate by about ten percent for natural color images. But even with these advances, mathematically lossless image compression (MLLIC) ratios for natural images still fall short of the bandwidth and cost-effectiveness requirements of most practical imaging and vision systems at present and beyond. To overcome the performance barrier of MLLIC, we question the very necessity of MLLIC. Considering that all digital imaging sensors suffer from acquisition noises, why should we insist on mathematically lossless coding, i.e., wasting bits to preserve noises? Instead, we propose a new paradigm of joint denoising and compression called functionally lossless image compression (FLLIC), which performs lossless compression of optimally denoised images (the optimality may be task-specific). Although not literally lossless with respect to the noisy input, FLLIC aims to achieve the best possible reconstruction of the latent noise-free original image. Extensive experiments show that FLLIC achieves state-of-the-art performance in joint denoising and compression of noisy images and does so at a lower computational cost.
@article{zhang2024fllic, title = {FLLIC: Functionally Lossless Image Compression}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {arXiv preprint arXiv:2401.13616}, year = {2024}, } - arXiv
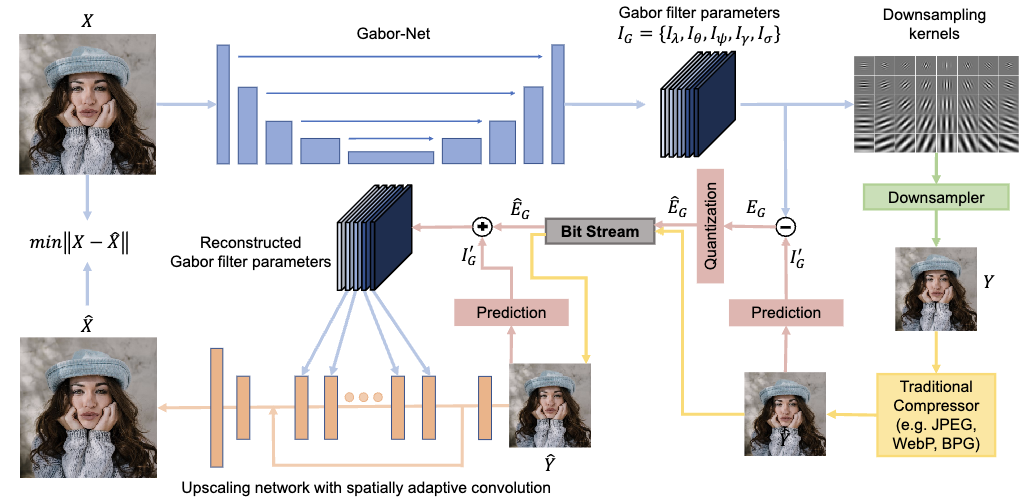 Dual-layer image compression via adaptive downsampling and spatially varying upconversionXi Zhang, and Xiaolin WuarXiv preprint arXiv:2302.06096, 2023
Dual-layer image compression via adaptive downsampling and spatially varying upconversionXi Zhang, and Xiaolin WuarXiv preprint arXiv:2302.06096, 2023Ultra high resolution (UHR) images are almost always downsampled to fit small displays of mobile end devices and upsampled to its original resolution when exhibited on very high-resolution displays. This observation motivates us on jointly optimizing operation pairs of downsampling and upsampling that are spatially adaptive to image contents for maximal rate-distortion performance. In this paper, we propose an adaptive downsampled dual-layer (ADDL) image compression system. In the ADDL compression system, an image is reduced in resolution by learned content-adaptive downsampling kernels and compressed to form a coded base layer. For decompression the base layer is decoded and upconverted to the original resolution using a deep upsampling neural network, aided by the prior knowledge of the learned adaptive downsampling kernels. We restrict the downsampling kernels to the form of Gabor filters in order to reduce the complexity of filter optimization and also reduce the amount of side information needed by the decoder for adaptive upsampling. Extensive experiments demonstrate that the proposed ADDL compression approach of jointly optimized, spatially adaptive downsampling and upconversion outperforms the state of the art image compression methods.
@article{zhang2023dual, title = {Dual-layer image compression via adaptive downsampling and spatially varying upconversion}, author = {Zhang, Xi and Wu, Xiaolin}, journal = {arXiv preprint arXiv:2302.06096}, year = {2023}, }